В рубрику "Оборудование и технологии" | К списку рубрик | К списку авторов | К списку публикаций
 Статья не излагает последовательную концепцию современного и уж тем более всякого будущего медиаархива. Содержание статьи сводится к перечислению нескольких почти случайно выбранных проблем, которые неизбежно возникнут при конструировании, разработке и внедрении цифрового медиаархива в реальное производство. Случайность выбора определяется тем, что по большей части будут рассмотрены только те проблемы, с которыми в телекомпании "Культура" уже успели столкнуться на собственной практике. По каждой рассматриваемой проблеме дается комментарий, цель которого - привести доказательства, убеждающие в существовании проблем, и наметить пути их решения
Статья не излагает последовательную концепцию современного и уж тем более всякого будущего медиаархива. Содержание статьи сводится к перечислению нескольких почти случайно выбранных проблем, которые неизбежно возникнут при конструировании, разработке и внедрении цифрового медиаархива в реальное производство. Случайность выбора определяется тем, что по большей части будут рассмотрены только те проблемы, с которыми в телекомпании "Культура" уже успели столкнуться на собственной практике. По каждой рассматриваемой проблеме дается комментарий, цель которого - привести доказательства, убеждающие в существовании проблем, и наметить пути их решения
Особенности перехода на цифру
К медиаконтенту относится широкий спектр используемых в медиаиндустрии материалов самых разнообразных типов и форматов (числовые данные, текст/гипертекст, двух-и трехмерная графика и изображения, звук, видео, кино и многое другое). Звук, видео, кино и некоторые другие в силу их специфики образуют отдельный класс медиаконтента - movie, если придерживаться терминологии, введенной одним из ключевых технологических "игроков" -компанией Apple Computer. Это класс медиаконтента оказался последним, вовлеченным в цифровую революцию, начавшуюся в медиаиндустрии в семидесятые годы прошлого столетия с появлением электронных издательских систем.
Проникновение цифры началось с внедрения цифровых форматов на отдельных стадиях медиапроизводства - собственно производство, редактирование, хранение и доставка звука, видео и кино (без сколько-нибудь существенных изменений самих технологических процессов). Полномасштабное проникновение современных информационных и телекоммуникационных технологий в сектора медиаиндустрии, имеющие дело с movie, - практика уже последнего десятилетия. Уже разработаны и широко используются частные технологические решения по управлению и обработке цифрового movie-контента, и следующий ожидаемый шаг - технологическая интеграция отдельных решений в единые информационно-коммуникационные комплексы, отвечающие традиционным бизнес-задачам медиаиндустрии на новом уровне и позволяющие ставить новые задачи.
 К ним относится, например, создание технологической и бизнес-инфраструктур для продажи movie-контента. Особенно это касается видеоконтента. Если годовой мировой объем продаж фотоархивов превышает 2 млрд долларов при 20%-ном годовом росте, то видеоархив продается, по разным оценкам, от 140 до 400 млн долларов в год. Однако Johnathan Klein, основатель и генеральный директор компании Getty Images, крупнейшего в мире продавца архивных фотоматериалов (а в последнее время и видео), утверждает, что по объему продаж архивное видео в ближайшие годы догонит архивное фото. Но ни продажи, ни производство медиаконтента не будут эффективными, если не обеспечить эффективный поиск медиаконтента.
К ним относится, например, создание технологической и бизнес-инфраструктур для продажи movie-контента. Особенно это касается видеоконтента. Если годовой мировой объем продаж фотоархивов превышает 2 млрд долларов при 20%-ном годовом росте, то видеоархив продается, по разным оценкам, от 140 до 400 млн долларов в год. Однако Johnathan Klein, основатель и генеральный директор компании Getty Images, крупнейшего в мире продавца архивных фотоматериалов (а в последнее время и видео), утверждает, что по объему продаж архивное видео в ближайшие годы догонит архивное фото. Но ни продажи, ни производство медиаконтента не будут эффективными, если не обеспечить эффективный поиск медиаконтента.
Сектора "новой" медиаиндустрии
Главными производителями, "хранителями" и потребителями звука, видео, кино и других movie-типов медиаконтента, безусловно, являются медиакомпании в традиционном их понимании. В Европе и США насчитывается 50 000 медиакомпаний, составляющих один из ключевых секторов медиаиндустрии, в котором занято 8 000 000 человек (GI-STICS Research). Но собственно медиакомпании - далеко не единственная категория компаний, ориентированных на movie-контент.
Другая большая и новая категория -крупные корпорации, работающие на массовом рынке, и государственные учреждения. Это новая тенденция была названа New Media Model. В статье J. Michael "Embrace Media or Die" (журнал "Worth", март 2001 года) объясняется, почему с переходом на онлайновые продажи крупные корпорации нанимают продюсеров из Голливуда и вынужденно становятся медиакомпаниями. В качестве примеров приведены столь различные компании, как Nike, Ford Motors и Charles Schwab и другие известные из списка Fortune 500. В целом список компаний, производящих и/или "хранящих", и/или потребляющих большие объемы видео-и иной movie-информации, весьма обширен:
Компании всех типов нуждаются в "правильных" цифровых медиархивах.
Потребности медиаиндустрии
На сегодня, в условиях принципиальной готовности технологических решений к внедрению, в подавляющем большинстве медиакомпаний остаются нерешенными многие насущные задачи:
Если медиаконтент как-то и описан, то самым простым и неэффективным для поиска способом, что тоже не способствует поиску и продаже контента.
Можно услышать многочисленные вопросы и диалоги, типичные для сегодняшнего состояния отрасли, подобные нижеперечисленным:
Ведущая функциональность: мотивы
При всей разумности и обоснованности длинных списков функциональных требований к медиаархивам было бы правильно выделить некую ведущую функциональность, желательно в количестве "одна штука". Необходимость выделения функциональности № 1 является соображением самого общего свойства, настолько общего, что как-то неловко очередной раз настаивать на этом. Но, к сожалению, общеизвестность соображения еще не означает его обязательность - наша собственная практика и, насколько мы могли понять, практика других компаний показывает, что пренебрежение общеизвестными и потому, казалось бы, обязательными соображениями вызывает столь же обязательные ошибки и уж точно приводит к бесплодным дискуссиям. К тому же мы следуем совету нашего старшего московского коллеги: "Если вы хотите, чтобы ваши аргументы были приняты, то одно и то же, для одной и той же аудитории следует повторить 9 раз (9 - число экспериментальное)".
Первая причина, по которой ведущая функциональность должна быть обязательно объявлена и принята к использованию, проста и очевидна: лучше, если система управления медиаархивом будет хорошо выполнять одну задачу, нежели много, но плохо. Вопрос только в том - какую задачу.
На первый взгляд эта причина выглядит как лозунг. На самом деле тут мы следуем вполне фундаментальной тенденции, практикуемой сегодня в индустрии информационных технологий, на которую будем ссылаться еще не раз. Разумеется, за тезис "Лучше хорошо выполнять одну задачу, нежели много, но плохо" приходится платить -мы сталкиваемся с теми же трудностями, что и нынче широко обсуждаемая конвергенция информационных и медиатехнологий. В данном случае эта трудность называется интеграцией (в смысле информационных технологий). Успокаивает то, что в самые последние годы на рынке информационных технологий появились интеграционные решения, которые либо стали поворачиваться к медиазадачам если не лицом, то хотя бы не спиной (IBM WebSphere, BEA Weblogic Microsoft BizTalk, Oracle lOg), либо полностью ориентированы на них (HP Digital Media Platform).
Вторая причина: объявленная и принятая функциональность № 1 представляет точку зрения, без которой невозможно судить о правильности выбора модели метаданных, форматов медиа-данных, структуры и архитектуры системы управления медиаархивом и прочих ее аспектов. Или здесь уместен упрек нашего американского коллеги: "Look but do not see" ("Смотрят, но не видят"). Короче, ведущая функциональность обеспечивает нас видением задачи и вполне определенным критерием выбора.
Ведущая функциональность: решение
Какую только обширную функциональность ни приписывают медиаархиву! Не будем здесь ее воспроизводить. Мы утверждаем, что ведущая функциональность любого, в частности, медиаархива сводится к обеспечению эффективного поиска материалов, накопленных в архиве. И на все, сказанное ниже, будем смотреть с точки зрения обеспечения эффективности поиска.
Однако в том общем виде, в каком пока сформулирована ведущая функциональность, она представляет собой не более чем призыв, поскольку оставляет изрядную неопределенность в ее интерпретации. Обратимся к общепринятому соображению - эффективность поиска определяется тем, насколько минимизированы ошибки поиска, которые принято разделять на ошибки двух родов. То есть требуется минимизировать потери искомой или, как говорят, релевантной информации (ошибки первого рода) и минимизировать информационный шум (ошибки второго рода).
Любой пользователь Интернета, обращаясь к поисковым системам, понимает эффективность поиска именно в таком смысле - его раздражает, когда предлагается не все то, что он ищет, и, наоборот, когда в большом количестве предлагается абсолютно лишняя информация. Самое замечательное, что Интернет-пользователь понимает эффективность поиска в указанном смысле, скорее всего, стихийно, а это один из серьезных аргументов в пользу такого, естественного, понимания эффективности. Итак, минимизация ошибок поиска и есть его эффективность.
Модель метаданных: медиаданные
В столь общей постановке задача эффективности поиска, скорее всего, неразрешима - вряд ли можно минимизировать ошибки для всех мыслимых семантических типов поиска, каждый их которых связан с одним или несколькими категориями медиаданных из многочисленного набора их категорий. Например, вряд ли режиссер документального кино, занятый поиском синхрона "что такой-то сказал о таком-то", и редактор новостийной службы, судорожно перед эфиром разыскивающий footage "вид Кремля зимним вечером в сильный снегопад", будут проводить поиск по семантически близким признакам. Поэтому синхрон требует своего описания, своего набора метаданных, а footage - своего. Мы привели относительно близкие примеры, а что если в этот ряд добавить, скажем, спектакли?
Чтобы дальше избежать путаницы в понятиях, напомним, что
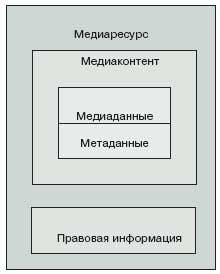
медиаконтент = медиаданные (медиаматериал) + метаданные (описания);
медиаресурс = медиаконтент + правовая информация.
Чтобы уйти от неразрешимости задачи описания медиаданных, универсального и одновременно "наилучшего" с точки зрения поиска, следует ограничить задачу в ее общности. Разумно разделить модель метаданных на некоторое универсальное ядро, общее для всех категорий медиаданных, и на расширения, специфические для каждой ее категории. Поэтому для начала нужно провести разбиение медиаданных на категории, отражающее "сходность-различие" запросов: запросы на поиск внутри одной категории должны быть семантически близкими и поэтому им нужно одинаково расширенное описание, для разных категорий медиаданных - далекими, и они, соответственно, потребуют разных расширенных описаний.
Итак, от общих соображений эффективности поиска мы приходим к практическим требованиям к модели метаданных, которая, с одной стороны, формализует приведенные выше и многие другие соображения. С другой стороны, модель метаданных играет роль исходных требований для структуры базы данных, обслуживающей эти самые метаданные. Более того, модель метаданных может повлиять и, скорее всего, повлияет на структуру и архитектуру информационного комплекса в целом. У общих соображений - "длинные руки".
Модель метаданных: объекты
Разнообразие категорий медиаданных еще не ограничивает все разнообразие метаданных. Вклад в разнообразие последних вносят также категории потребителей или, точнее, множество их потребностей. Например, некоторые категории потребителей вообще могут не интересоваться медиаматериалом - собственно медиаданными. Скажем, какие медиаданные содержит расписание эфира, которое верстается задолго до готовности медиаматериала, предназначенного для вещения? Ссылки на еще, быть может, несуществующий медиаматериал - да, но сам - нет. При этом расписание эфира уже является богатейшим источником метаданных. Или еще один, более убедительный пример - планирование человеческих, технических и финансовых ресурсов. Где там медиа? Опять же в лучшем случае ссылки. Наконец, киносериал из 999 серий или новостийная программа как бренд. На первый взгляд, чистой воды видеоматериал, но есть ли смысл позиционировать их как медиаданные?
В приведенных примерах мы ушли от собственно медиаархива в более широкую область медиапроизводства и вещания, но сделали это вполне сознательно, чтобы заимствовать полезные принципы, там разработанные и внедренные. В конце концов, медиаархив перестает быть складом медиаматериала. Одна только задача коммерческого использования, выполняемая на собственной информационной базе или через специализированного агента, существенно расширяет функции медиаархива и порождает новые задачи, для которых опыт производственных и вещательных компаний может быть весьма полезен.
Предмет продажи (так называемый "заказ"), конечно же, содержит ссылки на медиаданные, но там много и других "немедиа" метаданных:
Все это заставляет значительно расширить модель метаданных. Для начала напомним, что метаданные нужны не сами по себе, их задача - описывать некие предметы интереса, которые принято называть объектами. Или наоборот -объект это то, что подлежит описанию. Объекты весьма разнообразны: и эфирное расписание, и сериал, и короткий новостийный сюжет или footage.
Каждый объект и его метаданные проживают свой жизненный цикл:
рождение - модификация - потребление - смерть или "хранить вечно".
Жизненный цикл объекта и его метаданных привязан к условиям реального производства и/или внешнего потребления (продажам), точнее, к некоторым их компонентам, причем каждый объект к своим: какой-то к производству, другой к вещанию, третий к продажам или чему-то еще. Поэтому построение модели метаданных невозможно без того, чтобы модель могла быть наложена на производственный цикл, отчего она должна если не строиться полностью, то доводиться индивидуально для каждого отдельного производственного цикла. И потому прежде, чем приступать к выработке модели метаданных, к сожалению, придется заняться формализацией этого самого цикла производства, вещания и продаж.
Разумно все объекты модели разбить на две большие группы. Объекты первой группы привязаны к компонентам производства, хранения и/или потребления, напрямую не содержат медиаданные, но ссылаются на них (пример: планирование технических ресурсов). Объекты второй "свободны" от производства, "самодостаточны", непосредственно содержат метаданные и являются предметом ссылок со стороны объектов первой группы (примеры: новостийный сюжет и footage).
Продолжение следует
Начальник отдела службы развития ГТРК "Культура"
Виктор Мазо
Опубликовано: Журнал "Broadcasting. Телевидение и радиовещание" #1, 2005
Посещений: 11875
Статьи по теме
Автор
| |||
В рубрику "Оборудование и технологии" | К списку рубрик | К списку авторов | К списку публикаций
